赫尔辛基大学今天发表在NatureCommunications上的一篇新论文提出了一种准确分析癌症档案活检中基因组学数据的方法。该工具使用机器学习方法来纠正受损的DNA并揭示肿瘤样本中真正的突变过程。这有助于在数百万档案癌症样本中释放巨大的医学价值。
基于分子的诊断有助于将正确的患者与正确的癌症治疗相匹配。研究人员对临床癌症样本中的DNA分析特别感兴趣。
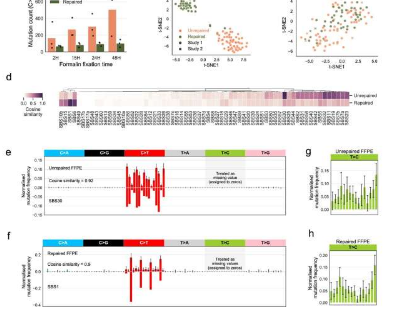
“由于DNA质量差,这一宝贵资源目前尚未用于分子诊断。福尔马林会对DNA造成严重损伤,因此对分析保存组织中的癌症基因组提出了不可避免的挑战,”赫尔辛基大学的主要作者郭庆丽说.
分析癌症基因组中的突变过程可以帮助早期发现癌症,准确诊断癌症,并揭示某些癌症对治疗产生抗药性的原因。新方法可以显着加速临床应用的开发,直接影响未来的癌症患者护理。
新方法预测了超过90%的癌症发展过程
主要作者郭庆利与伦敦癌症研究所(ICR)和伦敦玛丽女王大学的科学家密切合作,开发了名为FFPEsig的机器学习方法,以准确解开福尔马林如何突变DNA。
“我们的结果表明,如果没有噪声校正,通常会错过近一半的癌症过程。但是,使用FFPEsig,其中90%以上的过程被准确预测,”Qingli说。
癌症是逐渐演变的。分析纵向样本中的突变过程有助于识别临床信息预测因子并诊断每个肿瘤阶段。
“我们的发现能够从保存在室温下数十年的肿瘤活检样本中表征临床相关特征。随着对福尔马林如何影响癌症基因组的深入了解,我们的研究为利用巨额成本改造已开发的特征检测分析提供了巨大的机会-有效的档案样本,”研究人员说。
研究人员指出,该方法目前并不能完全去除FFPE样本中出现的显示批次效应的伪影,而且该工具的性能因癌症类型而异,因此必须小心解释任何发现。他们也有兴趣在未来进一步将他们的方法应用于更广泛的档案样本。